
Robots.txt Dosyası Nedir?
Robots.txt, web sitesi yöneticilerinin web robotlarına (genellikle arama motoru robotları) kullanıcılara sitelerinde nasıl gezineceklerini öğretmek için oluşturdukları bir metin dosyasıdır.
Robots.txt dosyası, robotların web’de gezinme, içeriğe erişim, dizine eklenim, ve bu içeriğin kullanıcılara sunulmasını düzenleyen web standartları üzerine kurulmuş bir grup olan (REP) protokolünün bir parçasıdır. REP, ayrıca meta robotlar gibi yönergelerin yanı sıra, arama motorlarının bağlantıları nasıl ele alması gerektiğine ilişkin sayfa, alt dizin veya site genelindeki talimatları (“takip et” veya “takipten çıkar” gibi) içerir.
Uygulamada, robots.txt dosyaları, kullanıcı aracılarının (web tarama yazılımı) bir web sitesinin bölümlerini tarayabileceğini veya tarayamayacağını belirtir. Bu tarama talimatları, belirli (veya tüm) kullanıcıların web sitesi üzerindeki hareketlerini “izin ver” veya “izin verme” komutları ile sınırlandırılır.
Temel Format
Bir robot dosyası birden fazla kullanıcı aracı ve yönerge satırı içerebilir. (Örneğin, “izin verme”, “izin ver”, “taramayı geciktir” v.b.)
Bu komut satırlarının tümü bir robots.txt dosyası kabul edilir. Bir robots.txt dosyasında, her bir kullanıcı aracısı yönerge kümesi, bir satır sonu ile ayrılmış, ayrı bir küme olarak işlenir.
Birden fazla kullanıcı aracısı yönergesi olan bir robots.txt dosyasında, “izin ver” veya “izin verme” komutlarının herbiri, yalnızca satırlara ayrılmış kümelerde belirtilen kullanıcı(lar) için geçerlidir. Dosyada birden fazla kullanıcı aracısı için geçerli bir komut varsa, tarayıcı yalnızca özellikle belirtilmiş talimat grubunun yönergelerini takip eder.

Msnbot, discobot ve Slurp’un hepsi spesifik komutlara atandığından, kullanıcı aracıları sadece robots.txt dosyasının direktiflerine göre işlenecektir. Diğer tüm kullanıcı aracıları ise, * grubundaki yönergeleri izleyecektir.
Robot.txt Örnekleri
example.com uzantısı için oluşturulmuş birkaç robots.txt örneği;
Robots.txt dosyası URL’si: www.example.com/robots.txt
Web tarayıcılarını içeriğin tümünden engelleme
User-agent: * Disallow: /
Bu sözdizimini bir robots.txt dosyasında kullanmak, tüm web tarayıcılarına -ana sayfa dahil- www.example.com adresindeki hiçbir sayfayı taramamasını söyler.
Web tarayıcılarına içeriğin tümünü taramasına izin vermek
User-agent: * Disallow:
Bu sözdizimini bir robots.txt dosyasında kullanmak, web tarayıcılarına -ana sayfa dahil- www.example.com adresindeki tüm sayfaları taramasını söyler.
Bir web tarayıcısını spesifik bir klasörden engellemek
User-agent: Googlebot Disallow: /example-subfolder/
Bu sözdizimi, yalnızca Google tarayıcısına (kullanıcı aracısı Googlebot), www.example.com/example-subfolder/ URL dizesini içeren sayfaları taramamasını söyler.
Bir web tarayıcısını spesifik bir web sayfasından engellemek
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Bu sözdizimi, www.example.com/example-subfolder/blocked-page adresindeki bir sayfayı taramamasını Bing’in tarayıcısına (kullanıcı aracısı Bing) bildirir.
Robot.txt Nasıl Çalışır?
Arama motorlarının iki ana görevi vardır:
- İnterneti yeni şeyler keşfetmek için taramak;
- İçeriği indeksleyerek bilgi edinmek isteyen kullanıcılara sunmak.
Arama motorları bir siteden diğerine ulaşmak için bağlantıları takip eder ve milyarlarca bağlantı ve web sitesinde gezinir. Bu tarama hareketi zaman zaman “örümcek” olarak da adlandırılır.
Bir web sitesine ulaşmadan önce, tarayıcı bir robots.txt dosyası arayacaktır. Arama sonucunda başarılı bir kaynak bulursa, sayfayı işlemeye devam etmeden önce bu dosyayı okur. Robots.txt dosyası, arama motorunun nasıl taranması gerektiği hakkında bilgi içerdiğinden, orada bulunan bilgiler bu sitede daha fazla tarayıcı eylemi yapılmasını sağlayacaktır. Robots.txt dosyası, bir kullanıcı aracısının etkinliğine izin vermeyen yönergeler içermiyorsa (veya site bir robots.txt dosyasına sahip değilse), sitedeki diğer bilgilere ulaşana kadar taramaya devam eder.
Robots.txt hakkında bilinmesi gereken diğer pratik bilgiler
- Aranan içeriğin bulunabilmesi için, robots.txt dosyası web sitesinin en üst dizinine yerleştirilmelidir.
- Robots.txt büyük/küçük harfe duyarlıdır. Bu yüzden dosya “robots.txt” olarak adlandırılmalıdır. (Robots.txt, robots.TXT veya başka bir varyasyon şeklinde değil.)
- Bazı kullanıcı aracı robotlar robots.txt dosyanızın sağladığı korumanın üstesinden gelebilir. Özellikle kötü amaçlı yazılım robotları ve e-posta adresinize zarar verebilecek tanımlanamayan uzantılar birçok tarayıcı arasında yaygındır.
- Bir web sitesi robots.txt dosyasına sahipse sitenin direktiflerini görmek için domain’in sonuna “robots.txt” eklemeniz yeterlidir. Bu, herkesin hangi sayfaları tarayıp taramak istemediğinizi görebileceği anlamına gelir; bu nedenle robots.txt yazılımını kişisel kullanıcı bilgilerinizi gizlemek için kullanmayın.
- Genellikle site haritalarının altında robots.txt dosyasıyla ilişkilendirilmiş bir uzantı bulunur. Örneğin;
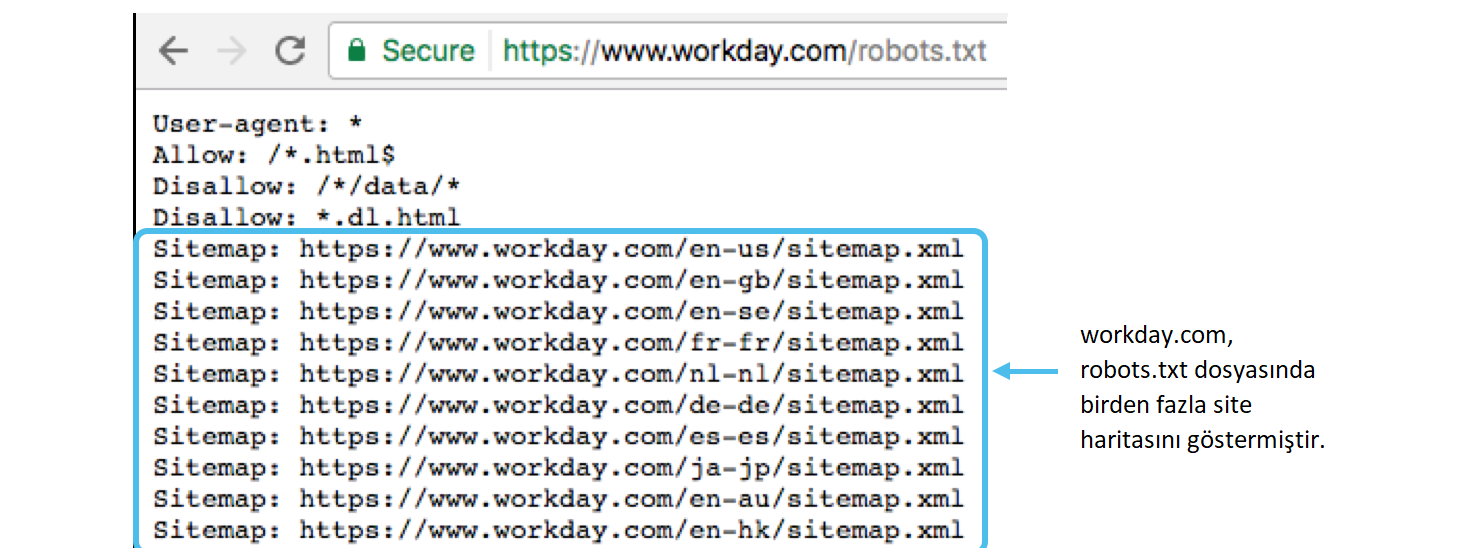
Robots.txt – Teknik Sözdizimi
Robots.txt sözdizimi
, robots.txt dosyalarının “dili” olarak düşünülebilir. Bir robot dosyasında karşılaşabileceğiniz beş genel terim vardır. Bunlar:
Kullanıcı aracısı: Tarama talimatlarını verdiğiniz belirli web tarayıcısıdır. (Genellikle bir arama motoru) Burada çoğu kullanıcı aracısının bir listesi bulunabilir.
Disallow (İzin Verme): Bir kullanıcı aracısına belirli URL’leri taramamasını söylemek için kullanılan komuttur. Her URL için yalnızca bir “Disallow:” satırına izin verilir.
Allow (İzin Ver): Googlebot’a ana sayfaya veya alt klasöre izin verilmese de bir sayfaya veya alt klasöre erişebileceğini söyleme komutu. *Sadece Googlebot için geçerlidir.
Crawl-delay (Taramayı Geciktir): Bir tarayıcının sayfa içeriğini yüklemeden ve taramadan önce kaç saniye beklemesi gerektiğini aktaran komuttur. Googlebot’un bu komutu kabul etmediğini unutmayın, ancak tarama hızı Google Arama Konsolu’nda ayarlanabilir.
Sitemap (Site Haritası): URL ile ilişkilendirilmiş herhangi bir XML site haritasının yerini bulmak için kullanılır. Bu komutun yalnızca Google, Ask, Bing ve Yahoo tarafından desteklendiğini unutmayın.
Engellenecek veya izin verilecek URL’lere gelince, robots.txt dosyaları, bir dizi olası URL seçeneğini kapsayacak şekilde kalıp eşleştirme kullanımına izin verdiklerinden durum oldukça karmaşık bir hal alabilir. Google ve Bing, bir SEO’nun dahil etmek istemediği sayfaları veya alt klasörleri tanımlamak için kullanılabilecek iki normal ifadeyi oluşturur. Bu iki karakter yıldız (*) ve dolar işaretidir ($).
- *, herhangi bir karakter sırasını temsil eden bir joker karakterdir.
- $, URL’nin sonunu temsil eder.
Google, burada olası kalıp eşleştirme sözdiziminin ve örneklerinin mükemmel bir listesini sunuyor.
Robots.txt bir sitede nerede yer alır?
Kullanıcılar bir siteye girdikleri zaman, arama motorları ve diğer web tarama robotları (Facebook’un tarayıcısı Facebot gibi) robots.txt dosyasını aramayı bilir. Ancak, bu dosyayı yalnızca belirli bir yerde ararlar: ana dizin (genellikle kök etki alanınız veya ana sayfanız) Bir kullanıcı aracısı www.example.com/robots.txt adresini ziyaret ederse ve orada bir robot dosyası bulamazsa, sitede bir robots.txt olmadığını düşünerek sayfadaki (ve hatta tüm sitedeki) her şeyi taramaya devam eder.
Robots.txt sayfası, ornek.com.tr/index/robots.txt veya www.ornek.com/homepage/robots.txt adresinde mevcut olsa bile, kullanıcı temsilcileri tarafından keşfedilmeyecek ve onları robots.txt dosyasına sahip olmayan bir web sitesini ziyaret ettikleri yanılgısına düşürecektir.
Robots.txt dosyanızın bulunmasını sağlamak için dosyayı ana domaininizde bulundurmaya lütfen özen gösterin.
Robots.txt’ye neden ihtiyaç duyarsınız?
Robots.txt dosyaları, sitenizin belirli alanlarına tarayıcı erişimini kontrol eder. Googlebot’un yanlışlıkla sitenizin tamamını taramasını engellemeniz (!) çok tehlikeli olsa da, bir robots.txt dosyasının çok kullanışlı olabileceği bazı durumlar vardır.
Bazı yaygın kullanım noktaları şunlardır:
- Kopyalanmış içeriğin SERP’lerde görünmesini engelleme (meta robotların genellikle bunun için daha iyi bir seçim olduğunu unutmayın)
- Bir web sitesinin tüm bölümlerini gizli tutma (örneğin, mühendislik ekibinizin hazırlık verileri)
- Dahili arama sonuçlarının herkese açık bir SERP’de gösterilmesini sağlamak
- Site haritasının konumunu belirleme
- Arama motorlarının web sitenizdeki belirli dosyaları endekslemesini önleme (resimler, PDF’ler, vb.)
- Tarayıcılara aynı anda birden fazla içerik yüklendiğinde sunucularınıza aşırı yüklenilmesini önlemek için tarama geciktirme süresi belirleme
Sitenizde, kullanıcı aracısı erişimini kontrol etmek istediğiniz alanlar yoksa, bir robots.txt dosyasına ihtiyacınız olmayabilir.
Robots.txt dosyasına sahip olup olmadığınızı nasıl kontrol edebilirsiniz?
Web sitenizin robots.txt dosyasına sahip olduğundan emin değil misiniz? Domainize kolayca erişin ve URL’nin sonuna /robots.txt ekleyin. Örneğin, Moz’un robot dosyası moz.com/robots.txt adresinde bulunur. Eğer bir .txt uzantılı dosya görünmüyorsa, aktif bir robots.txt dosyasına sahip değilsiniz anlamına geliyor.
Robots.txt dosyasını nasıl oluşturabilirsiniz?
Bir robots.txt dosyasına sahip olmadığınızdan eminseniz, yeni bir dosya oluşturmak son derece kolaydır. Google’un oluşturduğu bu makale robots.txt dosyası oluşturma işlemini detaylıca açıklıyor ve bu araç, dosyanızın doğru kurulup kurulmadığını test etmenize olanak tanıyor.
Robot dosyaları oluşturma konusunda pratik mi yapmak istiyorsunuz?
Bu yazımızın interaktif örneklerle pratik yapmanıza yardımcı olacağını düşünüyoruz.
Robots.txt mi Meta robots mu X-robots mu?
Maalesef çok fazla robot uzantılı dosya mevcut. Öyleyse bu üç tür robot talimatı arasındaki fark nedir? Öncelikle, robots.txt gerçek bir metin dosyasıdır, oysa meta ve x-robots meta direktifleridir. Üçü de farklı işlev gösterir. Robots.txt, site veya dizin çapında tarama yapılmasını sağlarken, meta ve x-robotları, indekslenen verileri bireysel sayfa (veya sayfa öğesi) şeklinde düzenleyebilir.
En iyi SEO uygulamaları
- Web sitenizin taranmasını istediğiniz hiçbir içeriğini engellemediğinizden emin olun.
- txt tarafından engellenen sayfalardaki bağlantılar taranmayacaktır. Bu da demek oluyor ki: Diğer arama motorlarına erişilebilen sayfalar (yani, robots.txt, meta robotlar veya başka bir yolla engellenmeyen sayfalar) bağlantılı olmadıkça, kaynaklar taranmayacak ve dizine eklenmeyecektir. Engellenen sayfalar arası veri eşitliği sağlanamaz. Eşitliğin sağlanmasını istediğiniz sayfalarınız varsa, robots.txt dışında farklı bir engelleme mekanizması kullanabilirsiniz.
- SERP sonuçlarında hassas verilerin (özel kullanıcı bilgileri gibi) görünmesini engellemek için robots.txt dosyasını kullanmayın. Diğer sayfalar doğrudan özel bilgiler içeren bir sayfaya (domaininizin ana sayfasındaki robots.txt yönergelerini atlayarak) bağlanabileceğinden, izin vermediğiniz dizine erişebilir. Sayfanızı arama sonuçlarından engellemek istiyorsanız, parola koruması veya noindex meta yönergesi gibi farklı yöntemler kullanabilirsiniz.
- Bazı arama motorlarında birden fazla kullanıcı aracısı vardır. Örneğin, Google, aramalar için Googlebot’u ve görsel arama için Googlebot-Image’i kullanır. Aynı arama motorundaki çoğu kullanıcı aracısı aynı komutlara göre hareket eder, böylece bir arama motorunun birden fazla tarayıcısının her biri için yönergeler ayrı komutlar atamanıza gerek kalmaz. Ancak bunu yapabilmeniz için site içeriğinizin nasıl taranacağını iyi ayarlayabilmeniz gerekir.
- Bir arama motoru robots.txt içeriğini önbelleğe alır, ancak genellikle önbellek içeriğini günde en fazla bir kez günceller. Dosyayı değiştirirmek ve olduğundan daha hızlı bir şekilde güncellemek istiyorsanız, robots.txt URL’nizi Google’a gönderebilirsiniz.




Robot.txt dosyası ile alakalı bilgi ararken ilk gördüğüm yazı ve gerçekten tatmin etti! İyi çalışmalar!
Merhaba,
Robot.txt dosyası benim en çok kafamı karıştıran şeylerden biriydi. Daha doğrusu ne olduğunu bile şuan bu yazıyı okuduğumda öğrendim. Ne işe yaradığını açık bir şekilde anlattığınız için teşekkürler.
Google’da Robot.txt dosyasını araştırırken sizi buldum. Yazdığınız bilgiler için teşekkürler araştırma yapmadan kurcalamak istemedim robot.txt dosyasını iyi çalışmalar
Robot.txt çok kafa karıştırıcı görünüyordu biraz araştırdım ve sizin sayfanızı buldum. Anlatımınız gerçekten çok güzel ve bilgilendirici teşekkürler.